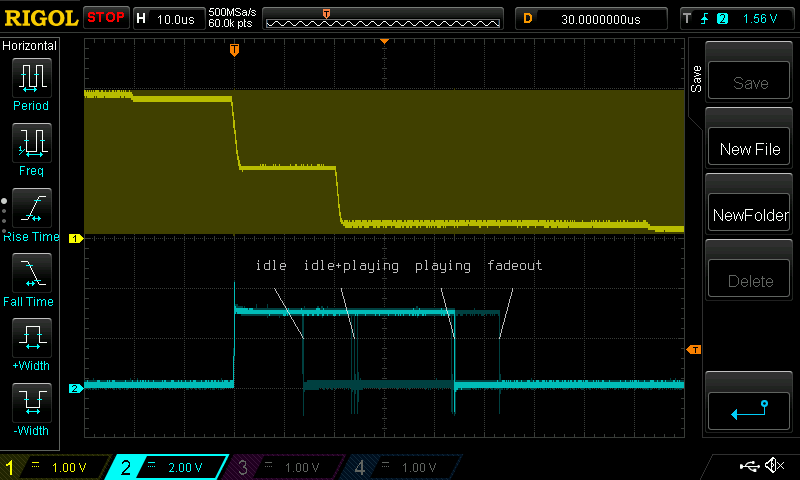
Yellow trace: Audio output. Cyan trace: CPU usage pulse.
Last January, I got the itch to make a sampler using Meson, ISO C11, STM32F4, and libopencm3. The project lulled midyear, but has become something I want to refine over time.
I forget sometimes that I ported libopencm3 to Meson only to use Meson and libopencm3 together for this project. I guess that’s how much I care to have good tooling, and how little I want to compromise on using a classic programming language.
How can I justify my choices? This is a greenfield hobby project. The goal is to have fun and do things that I’m not being paid to do. I wanted to explore my pet theories, draw inspiration from unlikely quarters. I always learn from a hobby project. At worst, I’ll become infinitesimally humbler.
I focused on programming in the small. I began with an interpolation function, the core of the sampling engine. Later came the sequencer. Then, a code generator to embed tight oneshots into the firmware image. I threw in stuff, like FreeRTOS integration, to see how I’d do that. Hey, I’ll make it cross-platform! Hey, I’ll write a way to test floating-point math! I pruned unused stuff over the past two weeks.
The embedded board I’m using has a button and some LEDs. That limits the functionality to toggling and indicating the transport state. The fun comes from the built-in DAC, which I run in 12-bit mode, whose tone is tastefully gritty. The DAC is driven by a DMA transaction clocked at 48kHz. The buffer holds 48 samples, so transactions zip by at a rate of 1kHz. Double buffering avoids a data race between the CPU and the DMA. The audio stream is solid.
Unlike on a hosted platform such as Linux, the purpose of the buffer isn’t to amortize I/O latency, which is almost zero. The system would run fine with an arbitrarily small buffer. However, this would increase the interrupt frequency, and there is some interrupt latency. I save some CPU cycles by interrupting less often.
Fortuitously, 1kHz is a good cadence for the sequencer. I used to drive the sequencer at audio rate, which was extremely accurate, but used more CPU than necessary. I don’t notice the sequencer’s 1ms resolution.
Most of the code is small, mathematically pure, platform-agnostic functions that compute an interesting scalar. Their behavior is specified by unit tests that run on POSIX. The speed, thoroughness, and ease of the test suite brings me delight in refactoring the code.
I toggle a GPIO pin before and after rendering the audio, which allows me to measure CPU usage using an oscilloscope. Sequencers and samplers are stateful brutes, and their CPU usage is state-dependent. This can make the worst-case CPU usage difficult to know, as it requires striking a surly simultaneity of states. As of today’s design, the maximum CPU usage is about 6%, nowhere near risking a buffer underrun. The state dependence might become a bother if, as I pile on the features, the states multiply like rabbits.
Yellow trace: Audio output. Cyan trace: CPU usage pulse.
Branchless programming is a hole for these rabbits, and I went down it. But I backed out for want of readable code. I might advance again if I can do it more humanly. The draw of branchless code isn’t to increase raw CPU performance by avoiding failed branch predictions—although the Cortex-M4F does have a five-stage pipeline. This is a realtime system. Branchless code can reduce the wobbliness of CPU usage so that I can do as much DSP as I can responsibly enjoy and still assuredly meet my 1ms deadline.
I dreamt big in the early days of the project. Time has given me realism. Being a dad, a husband, a homeowner, and a human leaves little time for side hustling. I’m a lucky man. I can at least hope that my luck continues.
Discuss this page by emailing my public inbox. Please note the etiquette guidelines.
© 2026 Karl Schultheisz